Loading...
loading...Sheet Copilot
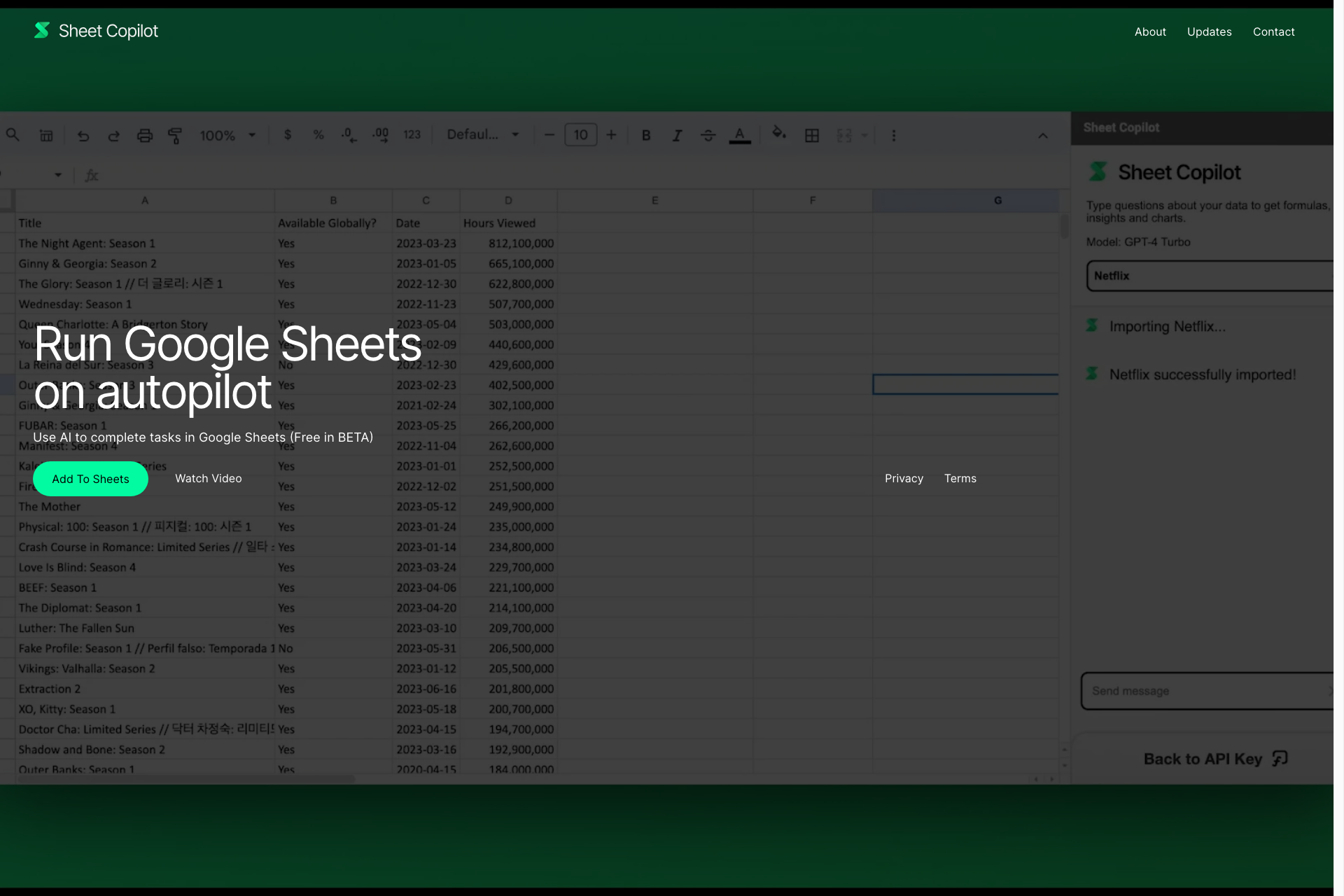
Run your Google Sheets on autopilot. Watch in real-time as Sheet Copilot takes on your tasks and answers your questions directly within Google Sheets.
Related Products about Sheet Copilot

Unlock the full potential of your business idea or venture with our meticulously crafted Notion template featuring the Business Model Canvas.

Undressbaby AI offers cutting-edge AI-powered virtual clothing try-ons, undressing simulations, and face swaps for both photos and videos, providing users with a fun and interactive fashion experience.

Meet Him AI Companion Assistant! Enjoy voice calls with a charming male AI. Make and receive calls for engaging chats, advice, and emotional support. Always ready for fun, heartfelt conversations anytime you need.

Personal childcare AI assistant app to support baby's sleep 1.Easy to record childcare, share with family member 2.Expert advice on sleep and childcare is available via AI chat 24 hours a day

A weekend hack of Infinite craft built by neil.fun a mini game where you can combine words together to make new stuff up.

Experience social media reimagined. No human users - just you and AIs. - Share posts, photos, and thoughts with AIs - See what's the AIs up to in your feed - Chat one-on-one with AIs through DMs - Explore diverse AI personalities

🚀 Dive into bilingual learning with Miraa AI! 🎥 Transcribe any video into bilingual subtitles. 📖 Learn with real-time translations, shadowing exercises, and AI-powered explanations.

AI Product Report is a service that provides a database and monthly reports summarizing the latest generative AI product information. It allows users to quickly, efficiently, and comprehensively stay updated on the newest generative AI products.