Loading...
loading...Playment
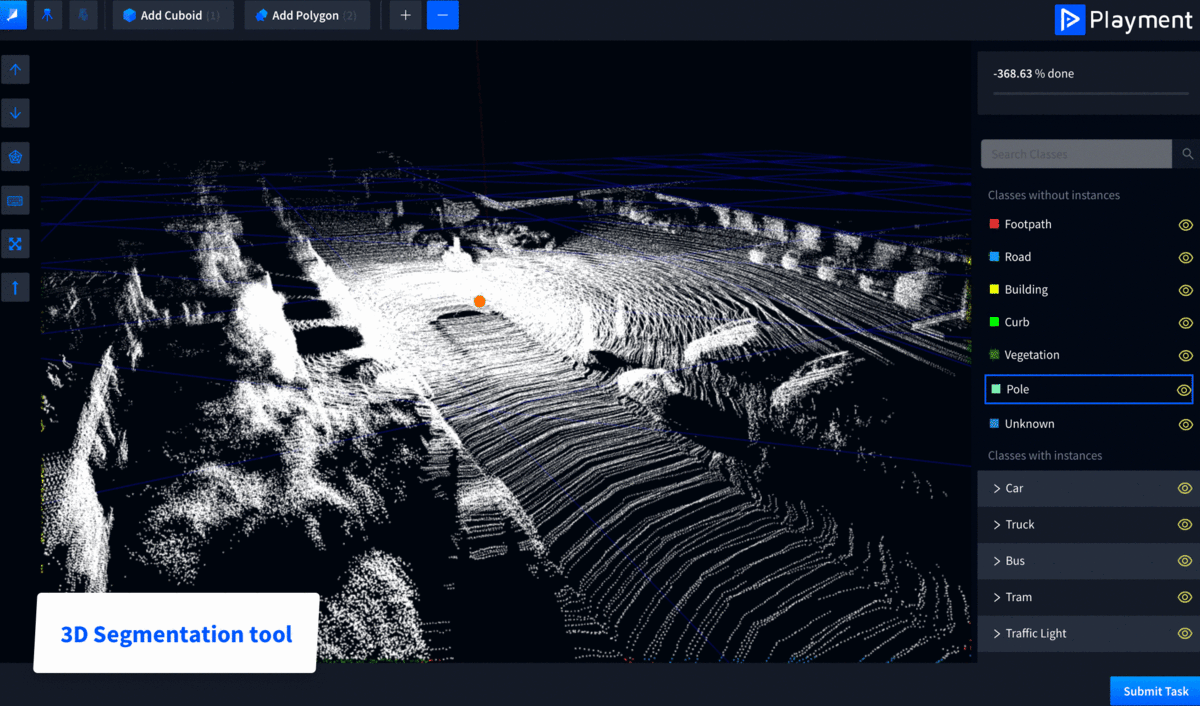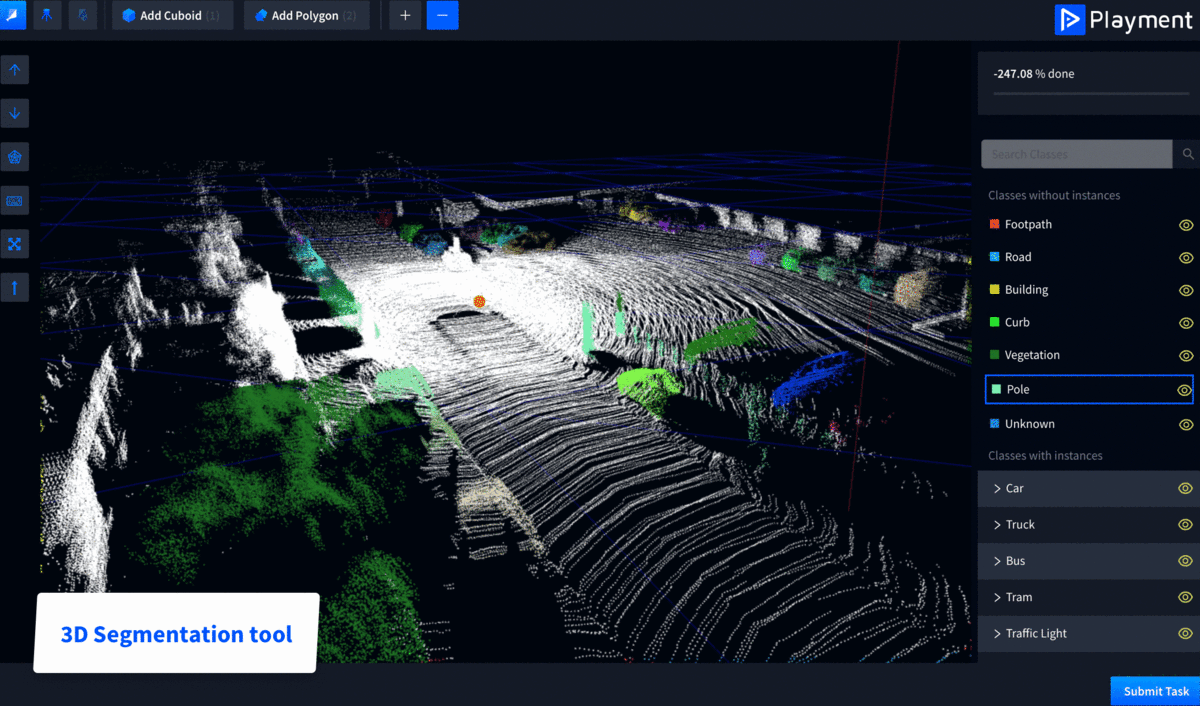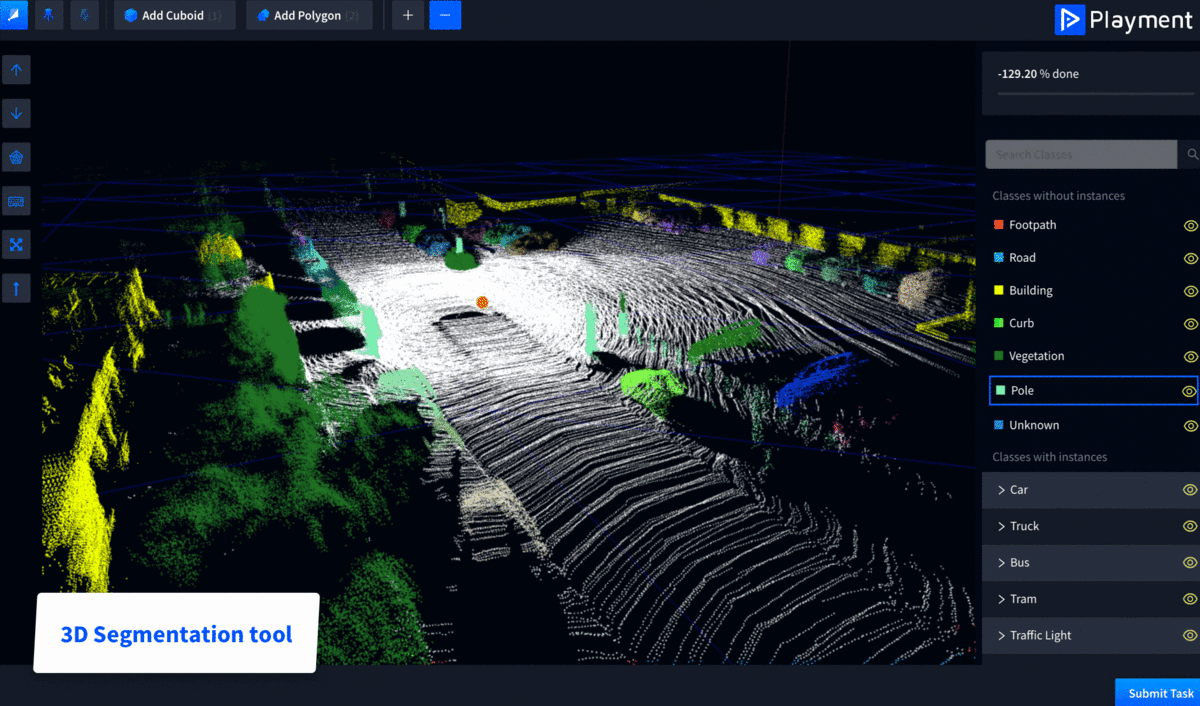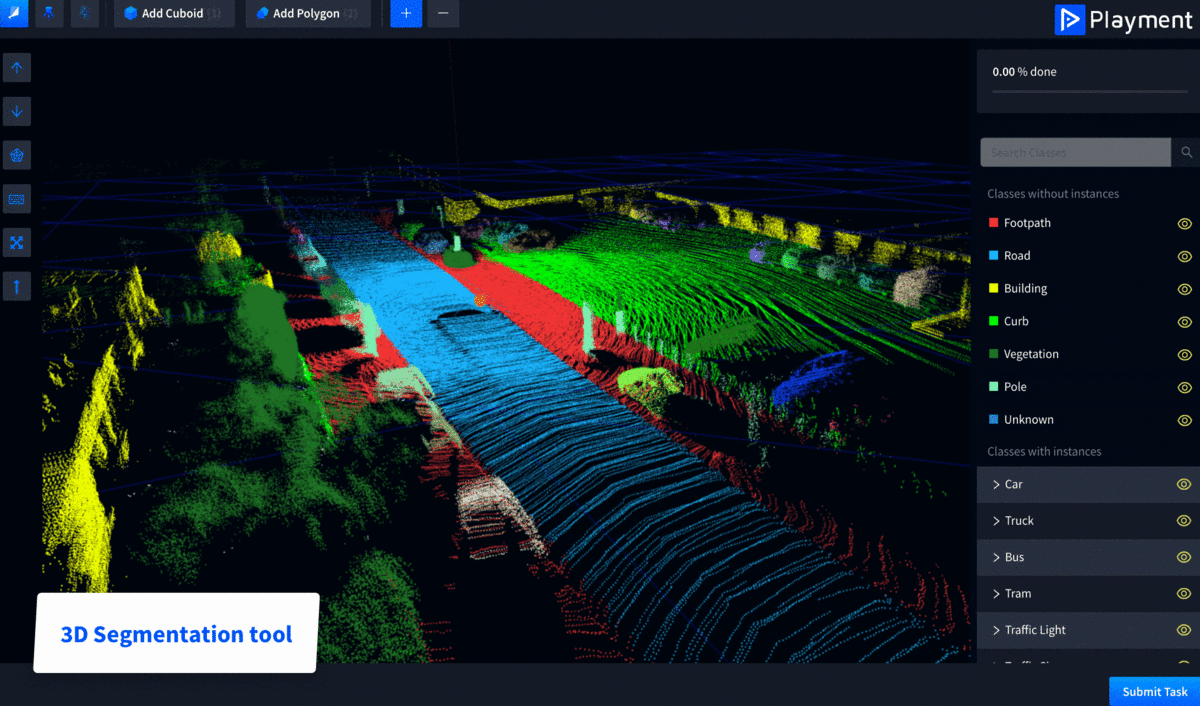
Playment is a fully managed data labeling platform generating training data for computer vision models at scale. We empower companies in the Autonomous Vehicle, Drones, Mapping, and similar spaces with high precision annotation services-No matter how complex. We’re helping companies and research institutions like Drive AI, Starsky Robotics, CYNGN, and UIUC focus on their core areas of development.
Related Products about Playment

Explore the capabilities of Sora. Discover the latest and trending videos and prompts generated by Sora at madewithsora.com 🙌

Build AI agents that can collaborate and access external tools, APIs, and real-time data, and perform actions on the client-side. With data validation, errors recovery, real-time responses, and long-term memory.. You can build reliable LLM-powered apps effortlessly. Just focus on your product's features and leave the rest to us. AI agents now can perform actions in the user's browser in real-time, unlocking a new level of interactive user experience!

faqbuddy is a free, efficient solution for instant FAQ responses using OpenAI's API. It offers robust functionality without monthly fees, suitable for Discord, Slack, Telegram, and WhatsApp, ensuring secure data management and continuous feature improvements.

Gather is building the next-generation personal assistant – a private AI that has full context about your life. With a single click, your AI “gathers” up all of your digital context – your Twitter likes, calendar entries, Kindle highlights etc. With that knowledge, your AI can answer any question about your past, your present, and sometimes even your future. Gather is privacy-first, so your data stays yours.

Tired of awkward and unreliable translations from Google Translate? Enter Langy, your go-to AI translator app that outshines the rest.

Create natural-sounding voiceovers with our text-to-speech AI Telegram Bot. Every text you type, the bot responds with automatically generated audio.

intersys is the AI directory that provides the best curated AI building blocks & AI systems so that all businesses & creators can systemise their operations, scale fast with automation and achieve their goals.
ChatTTS is a voice generation model on GitHub at 2noise/chattts,Chat TTS is specifically designed for conversational scenarios. It is ideal for applications such as dialogue tasks for large language model assistants, as well as conversational audio and video introductions. The model supports both Chinese and English, demonstrating high quality and naturalness in speech synthesis. This level of performance is achieved through training on approximately 100,000 hours of Chinese and English data. Additionally, the project team plans to open-source a basic model trained with 40,000 hours of data, which will aid the academic and developer communities in further research and development.